
Keen readers of this blog (hi Mom!) might have noticed my recent focus on neural networks and deep learning. It’s good for popularity, as deep learning posts are automatically cool (I’m really big in China now). Well, I’m going to leave the AI alone this time. In fact, this post won’t even really constitute data science. Instead, I’m going to explore a topic that has been on my mind and maybe produce a few graphs.
These days, my main interaction with modern music is through the radio at the gym. It wasn’t always like this. I mean I used to be with it, but then they changed what it was. I wouldn’t go so far as to say that modern music is weird and scary, but it’s certainly getting harder to keep up. It doesn’t help that songs now have about 5 people on them. Back in my day, you might include a brief rapper cameo to appear more edgy. So I thought I’d explore how song collaborations have come to dominate the charts.
Note that the accompanying Jupyter notebook can be viewed here. Let’s get started!
Scrapy
In my research, I came across a similar post. That one looked at the top 10 of the Billboard charts going back to 1990. Just to be different, I’ll primarily focus on the UK singles chart, though I’ll also pull data from the Billboard chart. From what I can tell, there’s no public API. But it’s not too hard to scrape the data off the official site. I’m going to use Scrapy. We’ll set up a spider to pull the relevant data and then navigate to the previous week’s chart and repeat that process until it finally reaches the first chart in November 1952. This is actually the first time I’ve ever used Scrapy (hence the motivation for this post), so check out its extensive documentation if you have any issues. Scrapy isn’t the only option for web scraping with Python (others reviewed here, but I like how easy it is to deploy and automate your spiders for larger projects.
import scrapy
import re # for text parsing
import logging
class ChartSpider(scrapy.Spider):
name = 'ukChartSpider'
# page to scrape
start_urls = ['http://www.officialcharts.com/charts/']
# if you want to impose a delay between sucessive scrapes
# download_delay = 0.5
def parse(self, response):
self.logger.info('Scraping page: %s', response.url)
chart_week = re.sub(' -.*', '',
response.css('.article-heading+ .article-date::text').extract_first().strip())
for (artist, chart_pos, artist_num, track, label, lastweek, peak_pos, weeks_on_chart) in \
zip(response.css('#main .artist a::text').extract(),
response.css('.position::text').extract(),
response.css('#main .artist a::attr(href)').extract(),
response.css('.track .title a::text').extract(),
response.css('.label-cat .label::text').extract(),
response.css('.last-week::text').extract(),
response.css('td:nth-child(4)::text').extract(),
response.css('td:nth-child(5)::text').extract()):
yield {'chart_week': chart_week, 'chart_pos':chart_pos, 'track': track, 'artist': artist,
'artist_num':re.sub('/.*', '', re.sub('/artist/', '', artist_num)),
'label':label, 'last_week':re.findall('\d+|$', lastweek)[0],
'peak_pos':re.findall('\d+|$', peak_pos)[0],
'weeks_on_chart':re.findall('\d+|$', weeks_on_chart)[0]}
# move onto next page (if it exists)
for next_page in response.css('.charts-header-panel:nth-child(1) .chart-date-directions'):
if next_page.css("a::text").extract_first()=='prev':
yield response.follow(next_page, self.parse)
Briefly explaining what happened there: We create a class called ChartSpider, essentially our customised spider (called ukChartSpider). We specify the page we want to scrape (start_urls). The spider then selects specific CSS elements (response.css()) within the page that contain the information we want (e.g. #main .artist a represents the artist’s name). These tags may seem complicated, but they’re actually quite easy to retrieve with a tool like Selector Gadget. Isolate the elements you want to extract and copy the css elements highlighted with the tool (see image below).
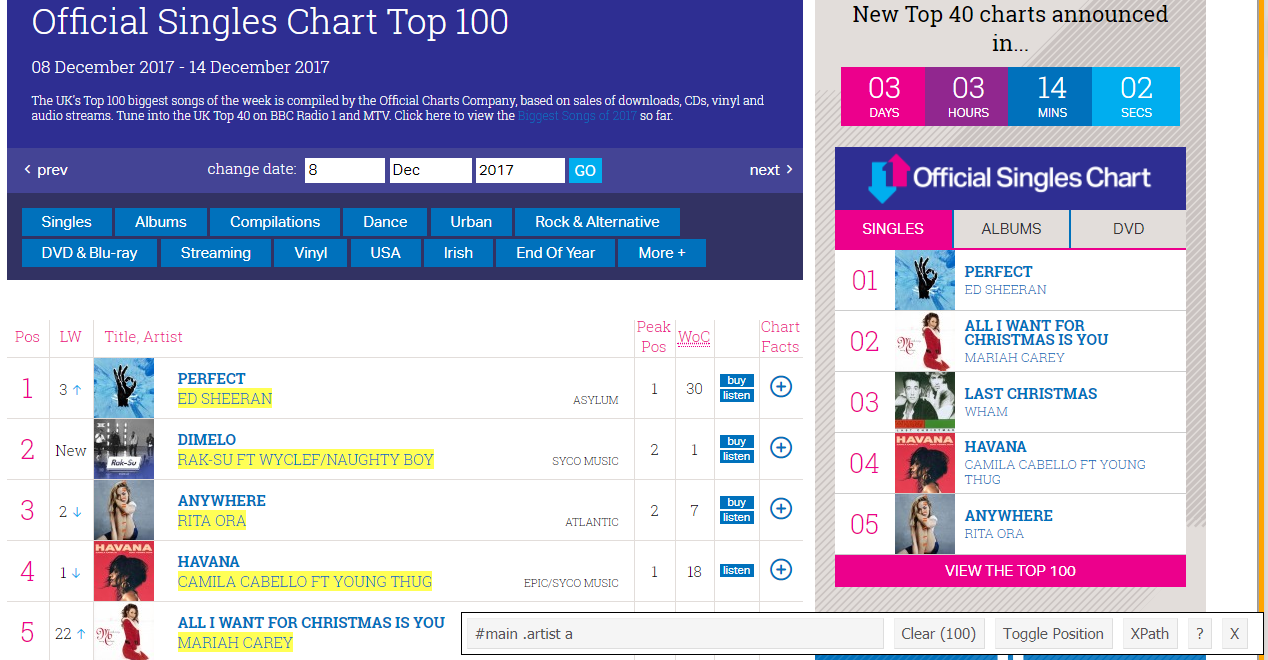
Finally, we’ll opt to write the spider output to a json file called uk_charts.json. Scrapy accepts numerous file formats (including CSV), but I went with JSON as it’s easier to append to this file type, which may be useful if your spider unexpectedly terminates. We’re now ready to launch ukChartSpider. Note that the process for the US Billboard chart is very similar. That code can be found in the accompanying Jupyter notebook.
from scrapy.crawler import CrawlerProcess
process = CrawlerProcess({
'USER_AGENT': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)',
'FEED_FORMAT': 'json',
'FEED_URI': 'uk_charts.json'
})
# minimising the information presented on the scrapy log
logging.getLogger('scrapy').setLevel(logging.WARNING)
process.crawl(ChartSpider)
process.start()
2017-12-18 23:26:29 [scrapy.utils.log] INFO: Scrapy 1.4.0 started (bot: scrapybot)
2017-12-18 23:26:29 [scrapy.utils.log] INFO: Overridden settings: {'FEED_FORMAT': 'json', 'FEED_URI': 'uk_charts.json', 'USER_AGENT': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)'}
2017-12-18 23:26:30 [ukChartSpider] INFO: Scraping page: http://www.officialcharts.com/charts/
2017-12-18 23:26:30 [ukChartSpider] INFO: Scraping page: http://www.officialcharts.com/charts/singles-chart/20171208/7501/
Pandas
If that all went to plan, we can now load in the json file as pandas dataframe (unless you changed the file path, it should be sitting in your working directory). If you can’t wait for the spider to conclude, then you can import the file directly from github (you can also find the corresponding Billboard Hot 100 file there- you might prefer downloading the files and importing them locally).
import pandas as pd
uk_charts = pd.read_json('uk_charts.json')
# convert the date column to the correct date format
uk_charts = uk_charts.assign(chart_week=pd.to_datetime(uk_charts['chart_week']))
uk_charts.head(5)
| artist | artist_num | chart_pos | chart_week | label | last_week | peak_pos | track | weeks_on_chart | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | ED SHEERAN | 6692 | 1 | 2017-12-08 | ASYLUM | 3 | 1 | PERFECT | 30 |
| 1 | RAK-SU FT WYCLEF/NAUGHTY BOY | 52716 | 2 | 2017-12-08 | SYCO MUSIC | 2 | DIMELO | 1 | |
| 2 | RITA ORA | 7418 | 3 | 2017-12-08 | ATLANTIC | 2 | 2 | ANYWHERE | 7 |
| 3 | CAMILA CABELLO FT YOUNG THUG | 51993 | 4 | 2017-12-08 | EPIC/SYCO MUSIC | 1 | 1 | HAVANA | 18 |
| 4 | MARIAH CAREY | 25943 | 5 | 2017-12-08 | COLUMBIA | 22 | 2 | ALL I WANT FOR CHRISTMAS IS YOU | 83 |
That table shows the top 5 singles in the UK for week starting 8st December 2017. I think I recognise two of those songs. As we’re interested in collaborations, you’ll notice that we have a few in this top 5 alone, which are marked with an ‘FT’ in the artist name. Unfortunately, there’s no consistent nomenclature to denote collaborations on the UK singles chart (the Billboard chart isn’t as bad).
| artist | artist_num | chart_pos | chart_week | label | last_week | peak_pos | track | weeks_on_chart | |
|---|---|---|---|---|---|---|---|---|---|
| 128157 | WEST END FEAT. SYBIL | 41240 | 8 | 1993-02-14 | PWL SANCTUARY | 4 | 3 | THE LOVE I LOST | 6 |
| 98974 | JODE FEATURING YO-HANS | 7134 | 75 | 1998-12-20 | LOGIC | 48 | 48 | WALK... (THE DOG) LIKE AN EGYPTIAN | 2 |
| 89799 | MUTINY FEAT D-EMPRESS | 9653 | 100 | 2000-09-24 | AZULI | 100 | NEW HORIZONS | 1 | |
| 1 | RAK-SU FT WYCLEF/NAUGHTY BOY | 52716 | 2 | 2017-12-08 | SYCO MUSIC | 2 | DIMELO | 1 | |
| 69097 | DJ SAMMY AND YANOU FT DO | 3502 | 98 | 2004-09-12 | DATA/MOS | 100 | 1 | HEAVEN | 28 |
| 11 | SELENA GOMEZ & MARSHMELLO | 52496 | 12 | 2017-12-08 | INTERSCOPE | 9 | 9 | WOLVES | 6 |
| 31974 | SOLDIERS WITH ROBIN GIBB | 25894 | 75 | 2011-10-30 | DMG TV | 75 | I'VE GOTTA GET A MESSAGE TO YOU | 1 | |
| 4595 | KUNGS VS COOKIN' ON 3 BURNERS | 49557 | 96 | 2017-01-27 | 3 BEAT | 90 | 2 | THIS GIRL | 33 |
| 98596 | SLADE VS. FLUSH | 5538 | 97 | 1999-01-17 | POLYDOR | 30 | MERRY XMAS EVERYBODY '98 REMIX | 4 |
Okay, we’ve identified various terms that denote collaborations of some form. Not too bad. We just need to count the number of instances where the artist name includes one of these terms. Right? Maybe not.
| artist | artist_num | chart_pos | chart_week | label | last_week | peak_pos | track | weeks_on_chart | |
|---|---|---|---|---|---|---|---|---|---|
| 196512 | AC/DC | 16970 | 51 | 1978-06-04 | ATLANTIC | 51 | ROCK AND ROLL DAMNATION | 1 | |
| 129655 | BOB MARLEY AND THE WAILERS | 31532 | 5 | 1992-09-27 | TUFF GONG | 6 | 5 | IRON LION ZION | 3 |
| 203656 | BOB MARLEY & THE WAILERS | 31532 | 40 | 1975-09-21 | ISLAND | 40 | NO WOMAN NO CRY | 1 |
I’m a firm believer that domain expertise is a fundamental component of data science, so good data scientists must always be mindful of AC/DC and Bob Marley. Obviously, these songs shouldn’t be considered collaborations, so we need to exclude them from the analysis. Rather than manually evaluating each case, we’ll discount artists that include ‘&’, ‘AND’, ‘WITH’, ‘VS’ that registered more than one song on the chart (‘FT’ and ‘FEATURING’ are pretty reliable- please let me know if I’m overlooking some brilliant 1980s post-punk new wave synth-pop group called ‘THE FT FEATURING FT’). Obviously, we’ll still have some one hit wonders mistaken as collaborations. For example, Derek and the Dominoes had only one hit single (Layla); though we’re actually lucky in this instance, as the song was rereleased in 1982 under a slight different name.
| artist | artist_num | chart_pos | chart_week | label | last_week | peak_pos | track | weeks_on_chart | |
|---|---|---|---|---|---|---|---|---|---|
| 181904 | DEREK AND THE DOMINOES | 14664 | 68 | 1982-02-28 | RSO | 68 | LAYLA {1982} | 1 | |
| 211792 | DEREK AND THE DOMINOES | 14664 | 25 | 1972-08-06 | POLYDOR | 25 | LAYLA | 1 |
uk_charts = pd.merge(uk_charts,
uk_charts.groupby('artist').track.nunique().reset_index().rename(
columns={'track': 'one_hit'}).assign(one_hit = lambda x: x.one_hit==1)).sort_values(
['chart_week', 'chart_pos'], ascending=[0, 1]).reset_index(drop=True)
uk_charts.head()
| artist | artist_num | chart_pos | chart_week | label | last_week | peak_pos | track | weeks_on_chart | one_hit | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | ED SHEERAN | 6692 | 1 | 2017-12-08 | ASYLUM | 3 | 1 | PERFECT | 30 | False |
| 1 | RAK-SU FT WYCLEF/NAUGHTY BOY | 52716 | 2 | 2017-12-08 | SYCO MUSIC | 2 | DIMELO | 1 | True | |
| 2 | RITA ORA | 7418 | 3 | 2017-12-08 | ATLANTIC | 2 | 2 | ANYWHERE | 7 | False |
| 3 | CAMILA CABELLO FT YOUNG THUG | 51993 | 4 | 2017-12-08 | EPIC/SYCO MUSIC | 1 | 1 | HAVANA | 18 | True |
| 4 | MARIAH CAREY | 25943 | 5 | 2017-12-08 | COLUMBIA | 22 | 2 | ALL I WANT FOR CHRISTMAS IS YOU | 83 | False |
We’ve appended a column denoting whether that song represents that artist’s only ever entry in the charts. We can use a few more tricks to weed out mislabelled collaborations. We’ll ignore entries where the artist name contains ‘AND THE’ or ‘& THE’. Again, it’s not perfect, but it should get us most of the way (data science in a nutshell). For example, ‘Ariana Grande & The Weeknd’ would be overlooked, so I’ll crudely include a clause to allow The Weeknd related collaborations. With those caveats, let’s plot the historical frequency of these various collaboration terms.
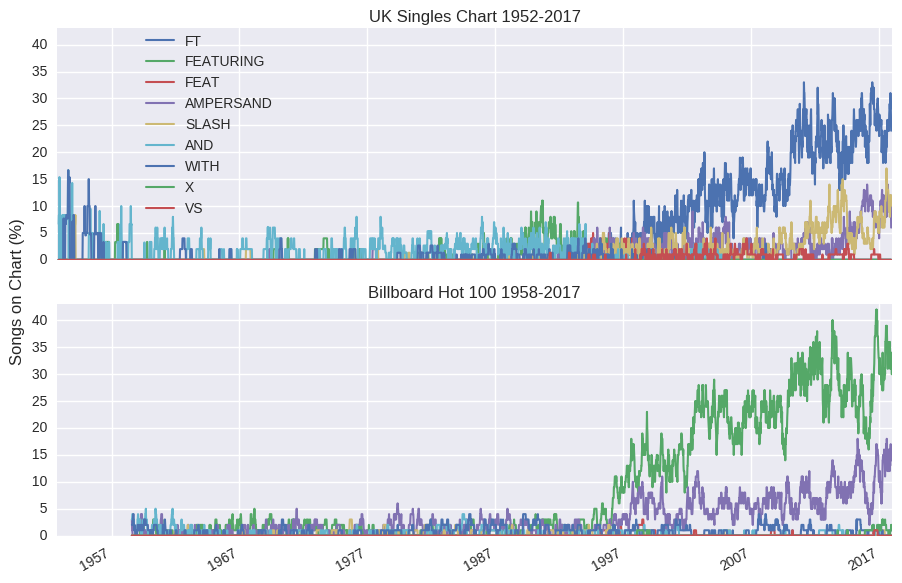
In the 1960s, 70s and 80s, colloborations were relatively rare (~5% of charted singles) and generally took the form of duets. Things changed in the mid 90s, when the number of colloborations increases significantly, with duets dying off and featured artists taking over. I blame rap music. Comparing the two charts, the UK and US prefer ‘ft’ and ‘featuring’, repsectively (two nations divided by a common language). The Billboard chart doesn’t seem to like the ‘/’ notation, while the UK is generally much more eclectic.
Finally, we can plot the proportion of songs that were collobarations (satisfied any of these conditions).
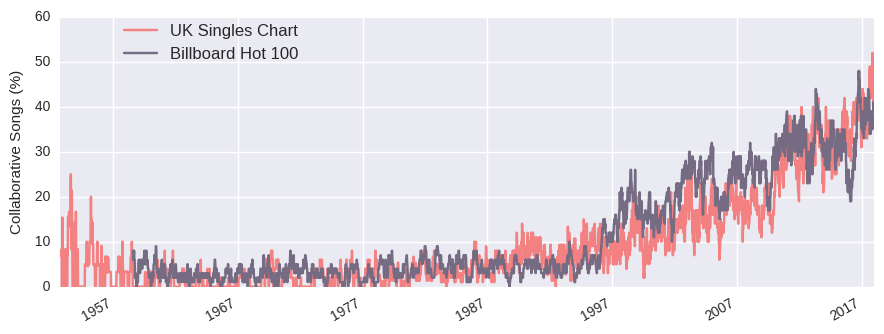
Clearly, collaborations are on the rise in both the US and UK, with nearly half of all charted songs now constituting collaborations of some form. I should say the Billboard chart has always consisted of 100 songs (hence the name), while the UK chart originally had 12 songs (gradually increasing to 50 in 1960 and 75 in 1978, finally settling on 100 in 1994). That may explain why the UK records high percentages in 1950s, as it would only require several colloborations.
Broadly speaking, the number of collaborations is pretty similar across the two countries. I suppose this isn’t surprising, as famous artists are commonly popular in both countries. Between 1995 and 2005, the proportion of collaborations runs slightly higher on the Billboard chart. Without any rigorous analysis to validate my speculations, I put this down to rap music. This genre tends to have more featured artists and I suspect it took longer for it to achieve mainstream popularity in the UK. Nevertheless, there’s no denying that collaborations are well on their way to chart domination.
Summary
Using Scrapy, we pulled historical data for both the UK Singles Chart and the Billboard Hot 100. We converted it into a Pandas dataframe, which allowed us to manipulate the artist names to distinguish collaborations and highlight of popularity of various collaboration types. Finally, we’ve illustrated the recent surge in song collaborations, which now account for nearly half of all songs on the chart.
So, that’s it. I apologise for the speculations and lack of cool machine learning. In my next post, I’ll return to artificial intelligence to predict future duets between current and now deceased artists (e.g. ‘Bob Marley & The Weeknd’). While you wait a very long time for that, you can download the historical UK chart and Billboard Top 100 files here or play around with the accompanying Jupyter notebook. Thanks for reading!
Leave a Comment